
Session objective
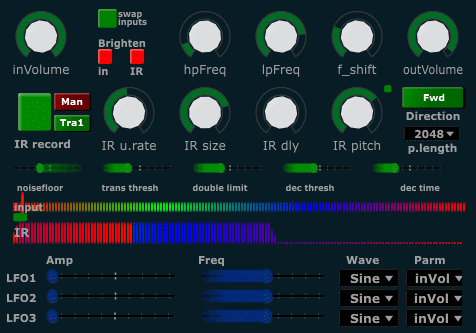
The session objective was to explore the live convolver , how it can affect our playing together and how it can be used. New convolver functionality for this session is the ability to trigger IR update via transient detection, as opposed to manual triggering or periodic metro-triggered updates. The transient triggering is intended to make the IR updating more intuitive and providing a closer interaction between the two performers. We also did some quick exploration of adaptive effects processing (not cross-adaptive, just auto-adaptive). The crossadaptive interactions can sometimes be complex. One way to familiarize ourselves with the analysis methods and the modulation mappings could be to allow musicians to explore how these are directly applied to his or her own instrument.
Kyle Motl: bass
Oeyvind Brandtsegg: convolver/singer/tech/camera
Live convolver
Several takes were done, experimenting with manual and transient triggered IR recording. Switching between the role of “recording/providing the impulse response” and of “playing through, or on, the resulting convolver”. Reflections on these two distinct performative roles were particularly friutful and to some degree surprising. Technically, the two sound sources of audio convolution are equal, it does not matter which way the convolution is done (one sound with the other, or vice versa). The output sound will be the same. However, our liveconvolver does treat the two signals slightly differently, since one is buffered and used as the IR, while the other signal is directly applied as input to the convolver. The buffering can be updated at any time, in such a fashion that no perceptible extra delay occurs due to that part of the process. Still, the update needs to be triggered somehow. Some of the difference in roles occur due to the need for (and complications of) the triggering mechanism, but perhaps the deepest difference occurs due to something else. There is a performative difference in the action of providing an impulse response for the other one to use, and the action of directly playing through the IR left by the other. Technically, the difference is minute, due to the streamlined and fast IR update. Perhaps also the sounding result will be perceptually indistinguishable for an outside listener. Still the feeling for the performer is different within those two roles. We noted that one might naturally play different type of things, different kinds of musical gestures, in the two different roles. This inclination can be overcome by intentionally doing what would belong to the other role, but it seem the intuitive reaction to the role is different in each case.
Video: a brief glimpse into the session environment.
Take 1: IR recorded from vocals, with a combination of manual and transient triggering. The bass is convolved with the live vocal IR. No direct (dry) signals was recorded, only the convolver output. Later takes in the session also recorded the direct sound from each instrument, which makes it easier to identify the different contributions to the convolution. This take serves more as a starting point from where we continued working.
Take 2: Switched roles, so IR is now recorded from the bass, and the vocals are convolved with this live updated IR. The IR updates were triggered by transient detection of the bass signal.
Take 3: As for take 2, the IR is recorded from bass. Changed bass mic to try to reduce feedback, adjusted transient triggering parameters so that IR recording would be more responsive
Video: Reflections on IR recording, on the roles of providing the IR as opposed to being convolved by it.
Kyle noticed that he would play different things when recording IR than when playing through an IR recorded by the vocals. Recording an IR, he would play more percussive impulses, and for playing through the IR he would explore the timbre with more sustained sounds. In part, this might be an effect of the transient triggering, as he would have to play a transient to start the recording. Because of this we also did one recording of manually triggered IR recording with Kyle intentionally exploring more sustained sounds as source for the IR recording. This seems to
even out the difference
(between recording IR and playing through it) somewhat, but there is still a
performatively different feeling
between the two modes.
When having the role of “IR recorder/provider”, one can be very active and continuously replace the IR, or leave it “as is” for a while, letting the other musician explore the potential in this current IR. Being more active and continuously replacing the IR allows for a closer musical interaction, responding quickly to each other. Still, the IR is segmented in time, so the “IR provider” can only leave bits and pieces for the other musician to use, while the other musician can directly project his sounds through the impulse responses left by the provider.
Take 4:IR is recorded from bass. Manual triggering of the IR recording (controlled by a button), to explore the use of more sustained impulse responses.
Video: Reflections on manually triggering the IR update, and on the specifics of transient triggered updates.
Take 5: Switching roles again, so that the IR is now provided by the vocals and the bass is convolved. Transient triggered IR updates, so every time a vocal utterance starts, the IR is updated. Towards the end of the take, the potential for faster interaction is briefly explored.
Video: Reflections on vocal IR recording and on the last take.
Convolution sound quality issues
The nature of convolution will sometimes create a muddy sounding audio output. The process will dampen high frequency content and emphasize lower frequencis. Areas of spectral overlap between two two signals will also be emphasized, and this can create a somewhat imbalanced output spectrum. As the temporal features of both sounds are also “smeared” by the other sound, this additionally contributes to the potential for a cloudy mush. It is welll known that brightening the input sounds prior to convolution can alleviate some of these problems. Further refinements have been done recently by Donahue, Erbe and Puckette in the ICMC paper “Extended Convolution Techniques for Cross-Synthesis” . Although some of the proposed techniques does not allow realtime processing, the broader ideas can most certainly be adapted. We will explore this further potential for refinement of our convolver technique.
As can be heard in the recordings from this session, there is also a significant feedback potential when using convolution in a live environment and the IR is sampled in the same room as it is directly applied. The recordings were made with both musicians listening to the convolver output over speakers in the room. If we had been using headphones, the feedback would not have been a problem, but we wanted to explore the feeling of playing with it in a real/live performance setting. Oeyvind would control simple hipass and lowpass filtering of the convolver output during performance, and thus had a rudimentary means of manually reducing feedback. Still, once unwanted resonances are captured by the convolution system, they will linger for a while in the system output. Nothing has been done to repair or reduce the feedback in these recordings, we keep it as a strong reminder that it is something that needs to be fixed in the performance setup. Possible solutions consist of exploring traditional feedback reduction techniques, but it could also be possible to do an automatic equalization based on the accumulated spectral content of the IR. This latter approach might also help output scaling and general spectral balance, since already prominent frequencies would have less poential to create strong resonances.
Adaptive processing
As a way to investigate and familiarize ourselves with the different analysis features and the modulation mappings of these signals, we tried to work on auto-adaptive processing. Here, features of the audio input affects effect processing of the same signal. The performer can then more closely interact with the effects and explore how different playing techniques are captured by the analysis methods.
Adaptive take 1: Delay effect with spectral shift. Short (constant) delay time, like a slapback delay or comb filter. Envelope crest controls the cutoff frequency of a lowpass filter inside the delay loop. Spectral flux controls the delay feedback amount. Transient density controls a frequency shifter on the delay line output.
Adaptive take 2: Reverb. Rms (amplitude) controls reverb size. Transient density controls the cutoff frequency of a highpass filter applied after the reverb, so that higher density playing will remove low frequencies from the reverb. Envelope crest controls a similarly applied lowpass filter, so that more dynamic playing will remove high frequencies from the reverb.
Adaptive take 3: Hadron. Granular processing where the effect has its own multidimensional mapping from input controls to effect parameters. The details of the mapping is more complex. The resulting effect is that we have 4 distinctly different effect processing settings, where the X and Y axis of a 2D control surface provides a weighted interpolation between these 4 settings. Transient density controls the X axis, and envelope crest controls the Y axis. A live excerpt of the controls surface is provided in the video below.
Video of the Hadron Particle Synthesizer control surface controlled by bass transient density and envelope crest.
Some comments on analysis methods
The simple analysis parameters, like rms amplitude and transient density works well on all (most) signals. However, other analysis dimensions (e.g. spectral flux , pitch , etc) have a more inconsistent relation between signal and analysis output when used on different types of signals. They will perform well on some instrument signals and less reliably on others. Many of the current analysis signals have been developed and tuned with a vocal signal, and many of them do not work so consistently for example on a bass signal. Due to this, the auto-adaptive control (as shown in this session) is sometimes a little bit “flaky”. The auto-adaptive experiments seems a good way to discover such irregularities and inconsistencies in the analyzer output. Still, we also have a dawning realization that musicians can thrive with some “livelyness” in the control output. Some surprises and quick turns of events can provide energy and creative input for a performer. We saw this also in the Trondheim session where rhythm analysis was explored , and in the discussion of this in the follow-up seminar . There, Oeyvind stated that the output of the rhythm analyzer was not completely reliable, but the musicians stated they were happy with the kind of control it gave, and that it felt intuitive to play with. Even though the analysis sometimes fail or misinterprets what is being played, the performing musician will react to whatever the system gives. This is perhaps even more interesting (for the musician), says Kyle. It creates some sort of tension, something not entirely predictable. This unpredictability is not the same as random noise. There is a difference between something truly random and something very complex (like one could say about an analysis system that misinterprets the input). The analyzer would react the same way to an identical signal, but give unproportionally large variance in the output due to small variances in the input. Thus it is a nonlinear complex response from the analyzer. In the technical sense it is controllable and predictable, but it is very hard to attain precise and determined control on a real world signal. The variations and spurious misinterpretations creates a resistance for the performer, something that creates energy and drive.

