
As preparation for upcoming discussions about tecnical needs in the project, it seems appropriate to briefly describe the current status of the software developed so far.
The plugins
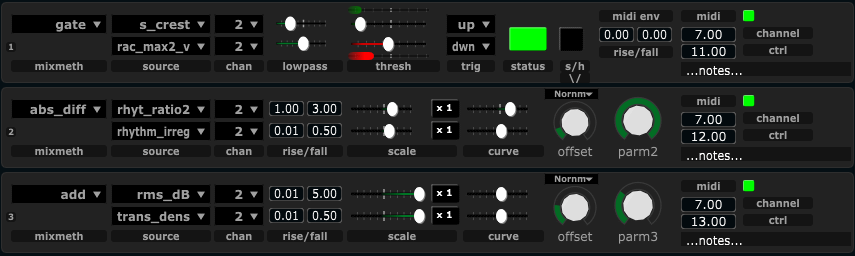
The two main plugins developed is the Analyzer and the MIDIator. The Analyzer extracts perceptual features from a live audio signal and transmit signals representing these features over a network protocol (OSC) to the MIDIator. The job of the MIDIator is to combine different analyzed features (scaling, shaping, mixing, gating) into a controller signal that we will ultimately use to control some effect parameter. The MIDIator can run on a different track in the same DAW, it can run on another DAW, or on another computer entirely.
Strong points
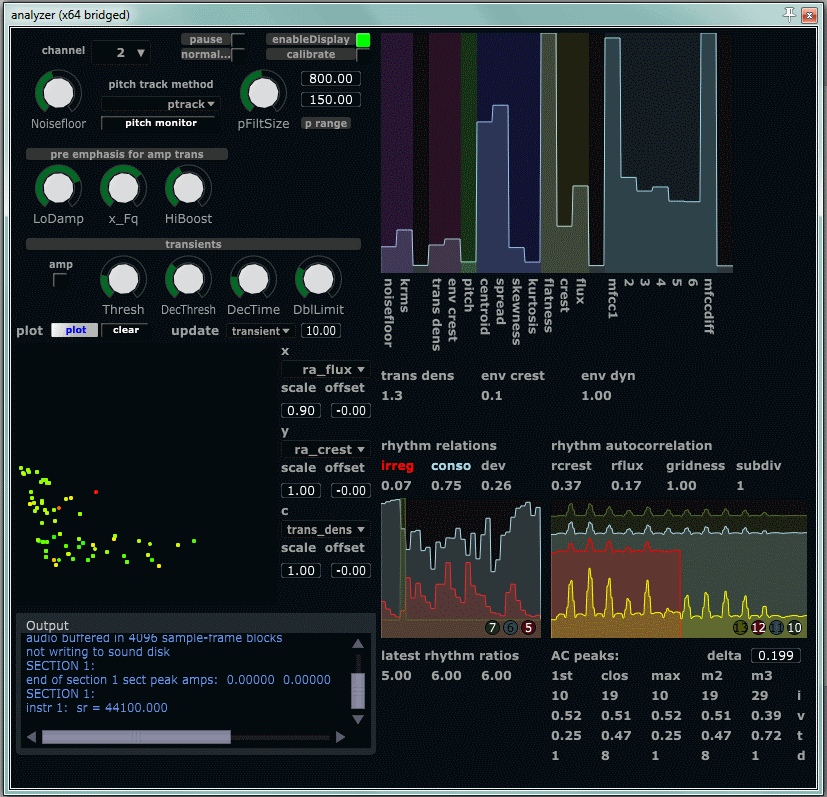
The feature extraction generally works reasonably well for the signals it has been tested on. Since a limited set of signals is readily available during implementation, some overfitting to these signals can be expected. Still, a large set of features is extracted, and these have been selected and tweaked for use as intentional musical controllers . This can sometimes differ from the more pure mathematical and analytical descriptions of a signal. The quality of of our feature extraction can best be measured in how well a musician can utilize it to intentionallly control the output. No quantitative mesurement of that sort have been done so far. The MIDIator contains a selection of methods to shape and filter the signals, and to combine them in different ways. Until recently, the only way to combine signals (features) was by adding them together. As of the past two weeks, mix methods for absolute difference, gating, and sample/hold has been added.
Weak points
The signal chain transmission from Analyzer to MIDIator, and then again from the MIDIator to the control signal destination each incurs at least one sample block latency. The size of a sample block can vary from system to system, but regardless of the size used our system will have 3 times this latency before an effect parameter value changes in response to a change in the audio input. For many types of parameter changes this is not critical, still it is a notable limitation of the system.
The signal transmission latency points at another general problem, interfacing between technologies. Each time we transfer signals from one paradigm to another we have the potential for degraded performance, less stability and/or added latency. In our system the interface from the DAW to our plugins will incur a sample block of latency, the interface between Csound and Python can sometimes incure performance penalties if large chunks of data needs to be transmitted from one to the other. Likewise, the communication between the Analyzer and MIDIator is such an interface.
Some (many) of the feature extraction methods create somewhat noisy signals. With noise, we mean here that the analyzer output can intermittently deviate from the value we perceptually assume to be “correct”. We can also look at this deviation statistically, if we feed it relatively (perceptually) consistent signals and look at how stable the output of each feature extraction method is. Many of the features show activity generally in the right register, and a statistical average of the output corresponds with general perceptual features. While the average values are good, we will oftentimes see spurious values with relatively high deviation from the general trend. From this, we can assume that the feature extraction model generally works, but intermittently fails. Sometimes, filtering is used as an inherent part of the analysis method, and in all cases, the MIDIator has a moving exponential average filter with separate rise and fall times. Filtering can be used to cover up the problem, but better analysis methods would give us more precise and faster response from the system.
Audio separation between instruments can sometimes be poor. In the studio, we can isolate each musician, but if we want them to be able to play together naturally in the same room, a significant bleed from one instrument to the other will occur. For live performance this situation is obviously even worse. The bleed give rise to two kinds of problems: Signal analysis is disturbed by the signal bleed, and signal processing is cluttered. For the analysis, it does not matter if we had perfect analysis methods if the signal to be analyzed is a messy combination of opposing perceptual dimensions. For the effect processing, controlling an effect parameter for one instrument leads to a change in the processing of the other instrument, just because the other instruments’ sound bleed into the first instrument’s microphones
Useful parameters (features extracted)
In many of the sessions up until now, the most used features has been amplitude (rms) and transient density. One reson for this is probably that they are concptually easy to understand, another is that their output is relatively stable and predictable in relation to the perceptual quality of the sound analyzed. Here are some suggestions of other parameters that expectedly can be utilized effectively in the current implementation:
- envelope crest ( env_crest ): the peakyness of the amplitude envelope, for sustained sounds this will be low, for percussive onsets with silence between evens it will be high
- envelope dynamic range ( env_dyn ): goes low for signals operating at a stable dynamic level, high for signals with a high degree of dynamic variation.
- pitch: well known
- spectral crest ( s_crest) : goes low for tonal sounds, medium for pressed tones, high for noisy sounds.
- spectral flux ( s_flux ): goes high for noisy sounds, low for tonal sounds
- mfccdiff: measure of tension or pressedness, described here
There is also another group of extracted features that is potentially useful but still has some stability issues
- rhythmic consonance ( rhythm_cons ) and rhythmic irregularity ( rhythm_irreg ): described here
- rhythm autocorr crest ( ra_crest ) and rhythm autocorr flux ( ra_flux ): described here
The rest of the extracted features can be considered more experimental, in some cases they might yield effective controllers, especially when combined with other features in reasonable proportions
Very interesting list of extracted features, and I truly enjoy the pragmatic approach where musical/artistic output takes precedence over mathematical rigor.
I suspect the latency should be of lesser concern than spurious outliers. Is there more to say about the characteristics of the feature noise? If it’s mostly single outliers wouldn’t median filtering be a better approach than the moving average filter?