As mentioned in the rhythm analysis part 1 , one of our goals at this point has been to try to find methods of rhythmical analysis that work without assumptions about pulse and meter, and also as far as possible without assumptions about musical style. As our somewhat minimal rhythm definition we look at rhythm as time ratio constellations , patterns of time ratios . Here we will make an assumption (yes, something must be assumed) regarding patterns of time durations: Recurring or repeated patterns have another perceptual quality than constantly shifting combinations of time durations. We could also assume that recurring or repeated patterns have stronger perceptual influence, but technically, it does not matter so much. The main issue is that we can measure some difference in quality. Quality here does not imply that something is better, just that something is different.
FFT of modified amplitude envelope
To measure how much recurrence there is in a signal, we can use autocorrelation. Repeated patterns will show up as peaks in the autocorrelation, and the period of repetition will be shown as the position of the peaks. Longer repetition periods give peaks further away (commonly further to the right when graphing the autocorrelation). To calculate the autocorrelation, we could use the FFT of the amplitude envelope as our basis. However, the unmodified envelope can have many variations at frequencies not related to the actual rhythms. For example, the amplitude envelope of a signal with fast transients (e.g. percussion, piano) show much more high frequency content than a signal with slow transients (e.g. many wind instruments). For this reason, we opted to use a modified envelope for the FFT in connection with the rhythm autocorrelation measure. The modified envelope is generated by using transient detection, triggering a short gaussian envelope scaled to the current amplitude of the signal. This way, we achieve a consistent envelope across different instruments, preserving the relative amplitude differences between transients (since we assume dynamics to be relevant to rhythm, for example in using accents to signify grouping of events).
Time spans and latency
One question to ask when analyzing for recurring patterns is “how long patterns are we looking for?” . One could say that a musical pattern sometimes will repeat relatively quickly, say once every second. Other times we can have arbitrary long patterns (sometimes very long), but for practical purposes, lets assume a maximum length of somewhere around 10 seconds. Now, if we want to analyze for such long patterns (10 seconds), an inherent limitation of any technique used would imply that it takes at least so many seconds to give an answer to whether there is a repeating pattern of that duration. Analyzing for 1-second patterns, we can have an indication after 1 second, and we can be sure after 2 seconds. For a musically responsive analysis, we’d like as low latency as possible, and in any practical case a latency of 10 seconds or more is not particularly responsive. Still, if the analysis window is shorter, we will not be able to detect longer patterns. One common method in FFT is to use overlapping windows, meaning that we update our analysis several times (with new data) within the time span defined by one analysis window. This will give us updated data more frequently, but still the longer patterns will only partially be influencing the output until a full period has passed. To alleviate this, we used 3 analysis durations running in parallel layers (each with overlapping windows as previously described). The longest time span is set to 10 seconds, layered onto this is a time span of 5 seconds, and layered on top of this again a 2.5 second time span. The layers are mixed down using a weighted sum that give precedence to more recent data while retaining the larger time span context. The shortest time span layer will be updated twice as often as the medium time span layer, and this again is updated twice as often as the longest time span layer. When we have a new frame of the longer time span, we will also have a new frame of the short time span ,these are then weighted 2/3 and 1/3 respectively. At the next available frame for the shorter time span, we weigh the new frame 2/3, and the longer frame 1/3. This is combined similarly for all the 3 layers to form the final autocorrelation coefficients. These are shown as a graph in the GUI.
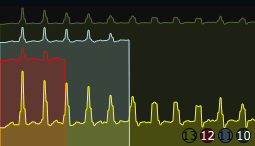
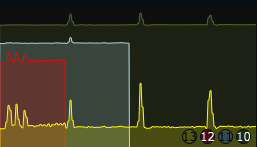
Features under development
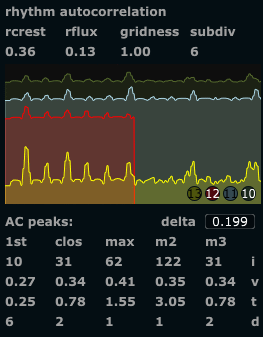
We have assumed that we could use the exact position of the peaks to detect the duration of repeated patterns . This is partly true, since fast rhythms (short repetition duration) give tightly spaced peaks, slow rhythms give sparsely spaced peaks. It seems so far, however, that the exact position and amplitude of each peak is not really stable enough to just use these values for that purpose. We use a peak picking algorithm to detect the highest peak, the second and third highest peak, and also the peak closest in time to the maximum peak and the first (earliest, leftmost) peak. In situations where the rhythm is quite static, these values correspond well to the repetition durations and the relative strength (in dynamics) of different repeating patterns. For most practical situations however, this specific application of the rhythmic autocorrelation does not really work that well (yet!). Another way of using these values could be to determine the degree to which the rhythmic events can be placed on a grid. We have termed this gridness . It is calculated by taking the maximum peak as the reference duration, then looking at the other detected peaks, and checking if we can find some relatively simple integer ratio between the max and each other peak. For example, if we have a max peak at 6 seconds, and then a second highest peak at 4 seconds, the ratio would be 3:2. In this case we construct a grid of 1/3 durations of the max peak across the whole time segment (1/3, 2/3, 3/3, 4/3, 5/3 … and so on as far as we can go), and see how many of all detected peaks correspond to grid locations. The process is repeated for each integer ratio found between the max peak and the lesser peaks. The grid with the maximum number of corresponding events wins, and is reported as the current rhythmic subdivision . The number of peaks that fall on this grid is divided by the number of detected events, resulting in the gridness value. If all detected events fall on grid locations, the gridness will be 1.0, if half of the events fall on the grid the gridness will be 0.5. The gridness measure does not currently work very well, due to the instability of the peaks as described above. This is an area of the analyzer where substantial refinement can take place. The resulting metrics (if working) however, seems intuitively to make sense; Measuring periods of repetition, subdivisions of these, and the degree of consistence with the assumed grid of subdivisions.
So what can we actually use it for now?
Following up on a suggestion from Miller Puckette, we tried to look at more general features of the correlation graph, to extract some global descriptors of the current rhythmic activity. We turned to well known statistics like
crest
and
flux .
The
crest
factor describing how “peaky” the signal is, that is the relation between the highest peak and the overall effective amplitude. Traditionally the crest would be calculated as the peak value divided by the rms (root-mean-square) amplitude. However, our use here is somewhat different than both the regular envelope crest and the spectral crest. For this specific purpose, we found it better to divide the rms value by the number of transients detected. This may at first seem counterintuitive, but can be explained by the fact that repeated patterns of the same duration creates many events that fall on the same peak locations in the autocorrelation, effectively making those peaks stronger. The division on the number of peaks detected avoids the exessively high crest values we could get if there was a single peak in the correlation. As such it gives a measure of the amount of repetition. It could be discussed whether we should use another term for this feature, to avoid confusion between this and the other creest measures.
The
flux
generally describes the
amount of change
from frame to frame, so
static patterns will have low flux while constantly shifting rhythms will have high flux.
The flux is calculated similarly as it would be for spectral flux (multiplying each value in a frame with the corrresponding value in the previous frame, accumulating the result and then normalizing it). This is done with a slight twist in our implementation; Because of the instability in the peaks’ location we don’t just multiply each value with the corresponding value of another frame, but we check if any neightbouring values have higher amplitude, and then use the maximum (this value or its neighbour on either side). We can think of this as the minimum possible flux. Empirical testing has shown it to be a more stable measure than the simpler variation of the flux measure.