Skype with Solveig Bøe, Simon Emmerson and Øyvind Brandtsegg.
The starting point and main focus of our conversation was the session that took place 20.-21. September in Studio Olavskvartalet, NTNU, and that is the theme of a former post on this blog. That post also contains audio takes and a video where the musicians discuss their experiences. Øyvind told us about what had been going on and about the reactions and reflections of the participants and himself. Simon had seen the video and listened to the takes, and Solveig will look at the material, try to use Merleau-Ponty’s language to describe the interactions going on.

One interesting case is when two (to make the system simple) musicians control each other, where for example the louder an instrument plays, the less effect of some kind on the other instrument, the louder the other instument plays the larger effect on the other. Simon had noted in the documentation that the participating musicians mentioned this (way of controlling each other) could lead to confusion. An analogy to playing football with two footballs was made, and the ball changing colour each time someone touched it. While not entirely similar in timing and pace, the image sheds some light on the added complexity. We discussed how this confusion could be reduced and how this could create interesting music. There is a learning curve involved and this must be tied to getting the musicians to know each other’s interaction patterns well, learning (by doing) how effects are created in each others sounds. Learning by listening and doing. But also by getting visual technical feedback? We all noted that the video documentation from the session made it particularly easy to gain insight into the session. More so than listening to the audio without video. There is an aspect of seeing the physical action, and also seeing the facial and bodily expression of the performers. Naturally, this in itself is not particular to our project, it also can be said of many recordings of performances. Still, since the phenomenon of cross-adaptiveness in the interaction can be a quite hard to grasp fully, this extra dimension of perception seems to help us engage when reviewing the documentation. That said, the video on the blog post was also very effectively edited by Andreas to extract significant points of interest and points of reflection. The editing also affects the perception of the event significantly of course. With that perspective, of the extra sensory dimension letting us engange more readily in the perception and understanding of the event, how could this be used to aid the learning process (for the performers)? Some of the performers also noted in the session interviews that some kind of visual feedback would be nice to have. Simon thought that visual feedback of the monitoring (of the sound) could be of good help. Øyvind also agrees to this, while at the same time also stressed that it could result in making the interactions between the musicians even more taxing, because they now also had to look at the screen, in addition to each other. Commonly in computer music performance, there has been a concern to get the performer’s focus away from the computer screen as it in many cases has been detrimental to the experience both for the performer and the audience. Providing a visual interface could lead to similar problems. Then again, the visual interface could potentially be used with success during the learning stage, to speed up the understanding of how the instrument (i.e. the full system of acoustic instrument plus electronic counterparts) works.
We discussed the confusion felt when the effects seemed difficult to control, the feeling of “ghostly transformations” taking place, the disturbances of the awareness of themselves and their “place”. Could confusion here be viewed as something not entirely negative too? Some degree of confusion could be experienced in terms of a pregnant complexity, to stimulate curiousness and lead to deeper engagement? How could we enable this flipping of sign for the confusion, making it more of a positive feature than a negative disorientation? Perhaps one aspect of this process is to provide just enough traction for the perception (in all senses) to hold on to the complex interactions. One way of reducing confusion would be to simplify the interactions. Then again, the analysis dimensions in this session were already simplified (just using amplitude and event density), and the affected modulation (relative balance between effects) also relatively simple. With respect to getting traction for perception to grasp the situation, experimentation with a visual feedback interface is definitely something that needs to be explored.

According to Merleau-Ponty interactions with others are variations in the same matter, something is the same for all participants, even if – and it always is – experienced from different viewpoints. What is the same in this type of interaction? Solveig said that to interact successfully there have to be something that is the same for all of the performers, they have to be directed towards something that is the same . But what could be a candidate for “ the same ” in a session where the participants interact with each others interactions? The session seems to be an evolving unity encompassing the perceptions and performances of the participants as they learn how ones instruments work in the “network” of instruments. Simon pointed to the book ‘Sonic Virtuality – Sound as Emergent Perception’ (Mark Grimshaw and Tom Garner – OUP 2015), that argues for the fact that no two sounds are ever the same. Neurophysiologically in each brain sounds are experienced differently, so we can’t say really that we hear the same sound. Solveig’s response was that the same is the situation where the participants create the total sound. In this situation one is placed, even if displaced by the effects created on one’s produced sounds. Displacement became a theme that we tried to reflect upon, the being “there” not “here”, by one being controlled by the other instrument(s). The dialectic between dislocation and relocation being important in this connection. Dislocation of the sound could feel like dislocation of oneself. How does amplification (generally in electroacoustic and electronic music) change the perspectives of oneself? How do we perceive the sound of a saxophone and the music performed on it differently when it is amplified so that the main acoustic impression of the instrument is coming to us through speakers? The speakers usually not being positioned in the same location as the acoustic instrument, and even if they were, the acoustic radiation patterns of the speakers would radically differ from the sound coming from the acoustic instrument. In our day and age, this type of sound reproduction and amplification is so common that we sometimes forget how it affects perception of the event. With unprocessed, as clean as possible or “natural” sound reproduction, the percepual effect is still significant. With processed sound even more so, and with the crossadaptive interactions the potential for dislocation and disconnection is manifold. As we (the general music loving population) have learned to love and connect to amplified and processed musics, we assume a similar process needs to take place for our new means of interaction. Similarly, the potential for intentionally exploring the dislocation effects for expressive purposes also can be a powerful resource.
Sound is in the brain, but also in the haptic, visual, auditory, in general, sensual, space. Phenomenologically what is going on in this space is the most interesting, according to Solveig, but the perspective from neuroscience is also something that could bring productive insights to the project.
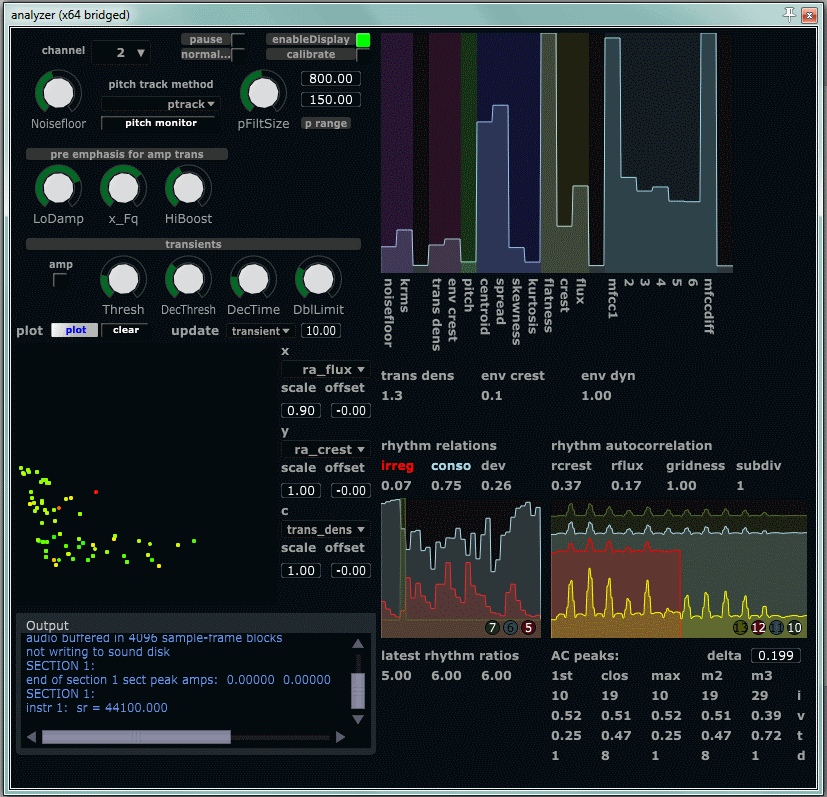
We returned to the question of monitoring: How much information should the performers get? What should they be able to control? Visualization of big data could help in the interaction and the interventions, but which form should the visualization have? Øyvind showed us an example of visualization from the Analyzer plugin developed in the project. Here, the different extracted features are plotted in three dimensions (x,y and colour) over time. It provides a way of getting insight into how the actual performed audio signal and the resulting analysis correlates. It was developed as a means of evaluating and selecting which features should be included in the system, but can potentially also be used directly by the performer trying to learn how the instrumental actions result in control signals.