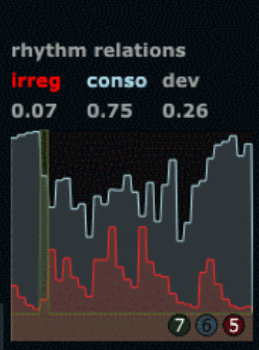
Jordan Morton is a bassist and singer, she regularly performs using both instruments combined. This provides an opportunity to explore how the liveconvolver can work when both the IR and the live input are generated by the same musician. We did a session at UCSD on February 22nd. Here are some reflections and audio excerpts from that session.
General reflections
As compared with playing with live processing, Jordan felt it was more “up to her” to make sensible use of the convolution instrument. With live processing being controlled by another musician, there is also a creative input from another source. In general, electronic additions to the instrument can sometimes add unexpected but desirable aspects to the performance. With live convolution where she is providing both signals, there is a triple (or quadruple) challenge: She needs to decide what to play on the bass, what to sing, explore how those two signals work together when convolved, and finally make it all work as a combined musical statement. It appears this is all manageable, but she’s not getting much help from the outside. In some ways, working with convolution could be compared to looping and overdubs, except the convolution is not static. One can overlay phrases and segments by recording them as IR’s, while shaping their spectral and temporal contour with the triggering sound (the one being convolved with the IR).
Jordan felt it
easier to play bass through the vocal IR than the other way around
. She tend to lead with the bass when playing acoustic on bass + vocals. The vocals are more an additional timbre added to complete harmonies etc with the bass providing the ground. Maybe the instrument
playing through the IR
has the opportunity of more actively shaping the musical outcome, while the IR record source is more a “provider” of an environment for the other to actively explore?
In some ways it can seem easier to manage the roles roles (of IR provider and convolution source) as one person than splitting the incentive among two performers. The roles becomes more separated when they are split between different performers than when one person has both roles and then switches between them. When having both roles, it can be easier to explore the nuances of each role. Possible to test out musical incentives by doing
this here
and then
this there
, instead of relying on the other person to immediately understand (for example to
*keep*
the IR, or to
*replace* it *now*
).
Technical issues
We explored transient triggered IR recording, but had a significant acoustic bleed from bass into the vocal microphone, which made clean transient trigging a bit difficult. A reliable transient triggered recording would be very convenient, as it would allow the performer to “just play”. We tried using manual triggering, controlled by Oeyvind. This works reliably but involves some guesswork as to what is intended to be recorded. As mentioned earlier (e.g.
in the first Olso session
), we could wish for a foot pedal trigger or other controller directly operated by the performer. Hey it’s easy to do, let’s just add one for next time.
We also explored continuous IR updates based on a metronome trigger. This allows periodic IR updates, in a seemingly streaming fashion. Jordan asked for an indication of the metronomic tempo for the updates, which is perfectly reasonable and would be a good idea to do (although had not been implemented yet). One distinct difference noted when using periodic IR updates is that the IR is
always
replaced. Thus, it is not possible to “linger” on an IR and explore the character of some interesting part of it. One could simulate such exploration by continuously re-recording similar sounds, but it might be more fruitful to have the ability to “hold” the IR, preventing updates while exploring one particular IR. This
hold
trigger could reasonably also be placed on a footswitch or other accessible control for the performer.
Audio excerpts
Take 1: Vocal IR, recording triggered by transient detection.
Take 2: Vocal IR, manually triggered recording
Take 3: Vocal IR, periodic automatic trigger of IR recording.
Take 4: Vocal IR, periodic automatic trigger of IR recording (same setup as for take 3)
Take 5: Bass IR, transient triggered recording. Transient triggering worked much cleaner on the bass since there was less signal bleed from voice to bass than vice versa.