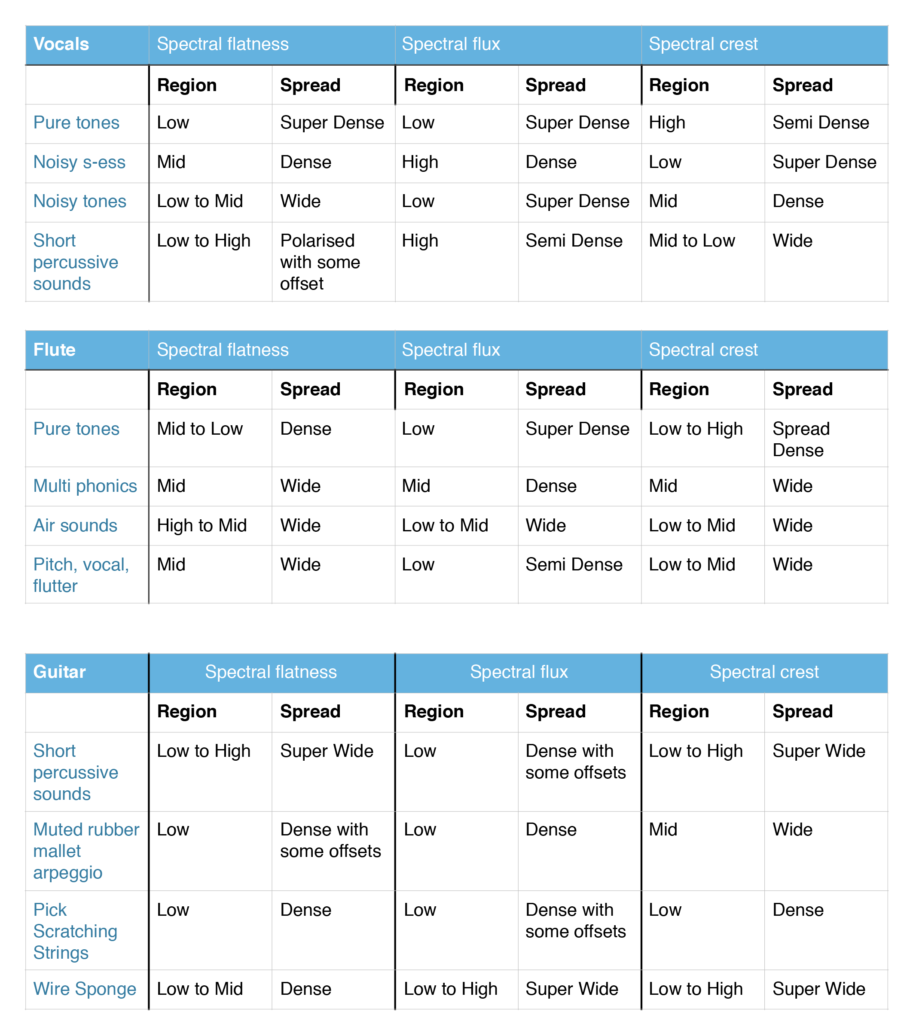
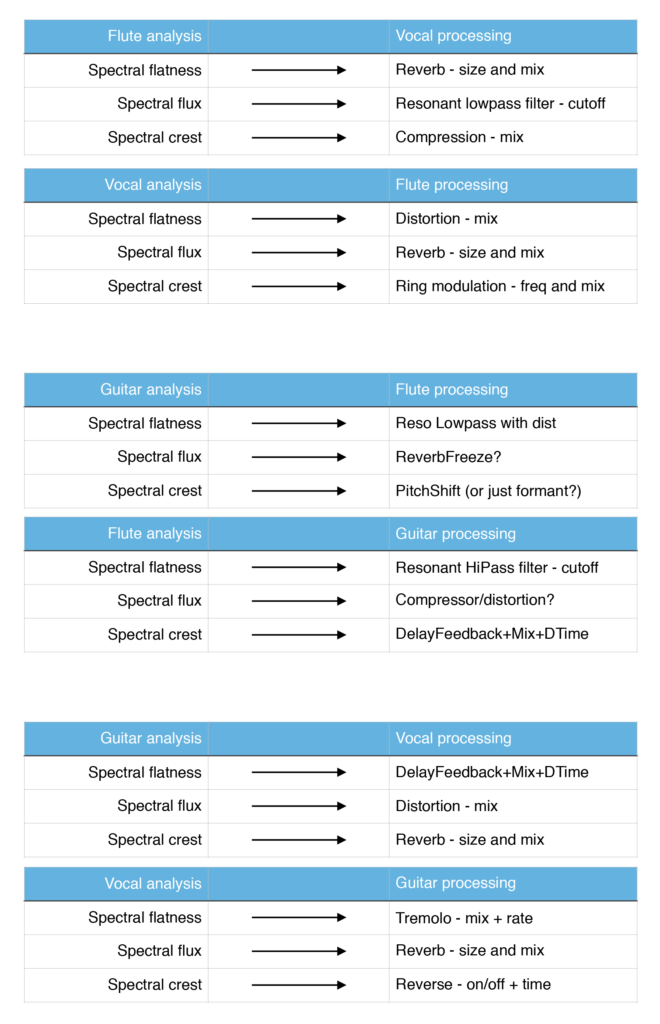
Since the crossadaptive project involves designing relationsips between performative actions and sonic responses, it is also about instrument design in a wide definition of the term. Some of these relationships can be seen as direct extensions to traditional instrument features, like the relationship between energy input and the resulting sonic output. We can call this
the mapping
between input and output of the instrument. Some other relationships are more more complex, and involves how the
actions
of one performer affect the
processing
of another. That relationship can be viewed as an
action
of one performer changing
the mapping
between input and output of another instrument. Maybe
another instrument
is not the correct term to use, since we can view all of this as one combined super-instrument. The situation quickly becomes complex. Let’s take as step back and contemplate for a bit on some of the separate aspects of a musical instrument and what constitutes its “moving parts”.
Playing on
the sound
One thing that has always inspired me with electric and electronic instruments is how the sound of the instrument can be tweaked and transformed. I know I have many fellow performers with me in saying that changing
the sound
of the instrument completely changes what you can and will play. This is of course true also with acoustic instrument, but it is even more clear when you can keep the physical interface identical but change the sonic outcome drastically. The comparision becomes more clear, since the performative actions, the physical interaction with the instrument does not need to change significantly. Still, when the sound of the instrument changes, even the physical gestures to produce it changes and so also what you will play. There is a connection and an identification between performer and sound, the current sound of the instrument. This als oextends to the amplification system and to the room where the sound comes out. Performers who has a lot of experience playing on big PA systems know the difference between “just” playing your instrument and playing the instrument through the sound system and in the room.
Automation in instruments
In this context, I have also mused on the subject of how much an instrument ‘does for you’. I mean, automatically, for example “smart” computer instruments that will give back (in some sense) more than you put in. Also, in terms of “creative” packages like Garageband and also much of what comes with programs like Ableton Live, where we can shuffle around templates of stuff made by others, like Photoshop beautifying filters for music. This description is not intended to paint a bleak picture of the future of creativity, but indeed is something to be aware of. In the context of our current discussion it is relevant because of the relation between input and output of the instrument; Garageband and Live, as instruments, will transform your input significantly according to their affordances. The concept is not necessarily limited to computer instruments either, as all instruments add ‘something’ that the performer could not have done by himself (without the external instrument). Also, as an example many are familiar with: playing through a delay effect: Creating beautiful rhythmic textures out of a simple input, where there may be a fine line between the moment
you are playing the instrument
, and all of a sudden
the instrument is playing you
, and all you can do is try to keep up. The devil, as they say, is in the delays!
Flow and groove
There is also a common concept among musicians, when the music flows so easily as if the instrument is playing itself. Being in the groove, in flow, transcendent, totally in the moment, or other descriptions may apply. One might argue that this phenomenon is also result of training, muscle memory, gut reaction, instinct. These are in some ways automatic processes. Any fast human reaction relies in some aspect on a learned response, processing a truly unexpected event takes several hundred milliseconds. Even if it is not automated to the same degree as a delay effect, we can say that there is not a clean division between automated and conteplated responses. We could probably delve deep into physchology to investigate this matter in detail, but for our current purposes it is sufficient to say automation is there to some degree at this level of human performance as well as in the instrument itself.
Another aspect of automation (if we in
automation
can include external events that triggers actions that would not have happened otherwise), or of “falling into the beat” is the synchronizing action when playing in rhythm with another performer. This has some aspects of similarity to the situation when “being played” by the delay effect. The delay processor has even more of a “chasing” effect since it will always continue, responding to every new event, non stop. Playing with another performer does not have that self continuing perpetual motion, but in some cases, the resulting groove might have.
Adaptive, in what way?
So when performing in a crossadaptive situation, what attitude could or should we attain towards the instrument and the processes therein? Should the musicians just focus on the acoustic sound, and play together more or less as usual, letting the processing unfold in its own right? From a traditionally trained performer perspective, one could expect the processing to adapt to the music that is happening, adjusting itself to create something that “works”. However, this is not the only way it could work, and perhaps not the mode that will produce the most interesting results. Another approach is to listen closely to what comes out of the processing. Perhaps to the degree that we disregard the direct sound of the (acoustic) instrument, and just focus on how the processing responds to the different performative gestures. In this mode, the performer would continually adjust to the combined system of
acoustic instrument
,
processing
,
interaction
with the other musician,
signal interaction
between the two instruments, also including any contribution from the
amplification
system and the
ambience
(e.g. playing on headphones or on a P.A). This is hard for many performers, because the complete
instrument system
is bigger, has more complex interactions, and sometimes has a delay from an action occurs to the system responds (might be a musical and desirable delay, or a technical artifact), plainly a larger distance to all the “moving parts” of the machinery that enables the transformation of a musical intent to a sounding result. In short, we could describe it as having a
lower control intimacy
. There is also of course a question of the willingness of the performer to set himself in a position where all these extra factors are allowed to count, as it will naturally render most of us in a position where we again are amateurs, not knowing how the instrument works. For many performers this is not immediately attractive. Then again, it is an opportunity to find something new and to be forced to abandon regular habits.
One aspect that I haven’t seen discussed so much is the
instrumental scope
of the performer. As described above, the performer may choose to focus on the acoustic and physical device that was traditionally called the instrument, and operate this with proficiency to create coherent musical statements. On the other hand, the performer may take into account the whole system (where does that end?, is it even contained in the room in which we perform the music?) of sound generation and transformation. Many expressive options and possibilities lies within the larger system, and the position of the listener/audience also oftentimes lies somewhere in the bigger space of this combined system. These reflections of course apply just as much to any performance on a PA system, or in a recording studio, but I’d venture to say they are crystallized even more clearly in the context of the crossadaptive performance.
Intellectualize the mapping?
To what degree should the performers know and care about the details of the crossadaptive modulation mappings? Would it make sense to explore the system without knowing the mapping? Just play. It is an attractive approach for many, as any musical performance situation in any case is complex with many unknown factors, so why not just throw in these ones too? This can of course be done, and some of our experiments in San Diego has been following this line of investigation (me and Kyle played this way with complex mappings, and the Studio A session between Steven an Kyle leaned towards this approach). The rationale for doing so is that with complex crossadaptive mappings, the intellectual load of just remembering all connections can override any impulsive musical incentive. Now, after doing this on some occasions, I begin to see that as a general method perhaps this is not the best way to do it. The system’s response to a performative action is in many cases so complex and relates to so many variables, that it is very hard to figure out “just by playing”. Some sort of training, or explorative process to familiarize the performer with the new expressive dimensions is needed in most cases. With complex mappings, this will be a time consuming process. Just listing and intellectualizing the mappings does not work for making them available as expressive dimensions during performance. This may be blindingly obvious after the fact, but it is indeed a point worth mentioning. Familiarization with the expressive potential takes time, and is necessary in order to exploit it. We’ve seen some very clear pedagogical approaches in some of the
Trondheim sessions
, and these take on the challenge of getting to know the full instrument in a step by step manner. We’ve also seen some very fruitful explorative approaches to performance in some of the
Oslo sessions
. Similarly, when Miller Puckette in our sessions in San Diego chooses to listen mainly to the processing (not to the direct sound of his instrument, and not to the direct sound of his fellow musician’s instrument, but to the combined result), he actively explores the farthest reaches of the space constituted by the instrumental system as a whole. Miller’s approach can work even if all the separate dimensions has not been charted and familiarized separately, basically because he focus almost exclusively on those aspects of the combined system output. As often happens in conversations with Miller, he captures the complexity and the essence of the situation in clear statements:
“The key ingredients of phrasing is time and effort.”
What about the analytical listener?
In our current project we don’t include any proper research on how this music is experienced by a listener. Still, we as performers and designers/composers are also experiencing the music as listeners, and we cannot avoid wondering how (or if) these new dimensions of expression affects the perception of the music “from the outside”. The different presentations and workshops of the project affords opportunities to hear how outside listeners perceive it. One recent and interesting such opportunity came when I was asked to present something for Katharina Rosenbergers Composition Analysis class at UCSD. The group comprised of graduate composition students, critical and highly reflective listeners, and in the context of this class especially aimed their listening towards analysis. W
hat is in there ? How does it work musically? What is this composition? Where is the composing?
In the discussions with this class, I got to ask them if they perceived it as important for the listener to
know and understand
the crossadaptive modulation mappings. Do they need to learn the intricacies of the interaction and the processing in the same pedagogical manner? The output from this class was quite clear on the subject:
I
t is the things they make the performers do that is important
In one way, we could understand it as a modernist stance that if it is in there, it will be heard and thus it matters. We could also understand it to mean that the
changes
in the interaction, the thing that performers will do
differently
in this setting is what is the most interesting. When we hear surprise (in the performer), and a subsequent change of direction, we can follow that
musically
without knowing about the exact details that led to the surprise.